
はじめに ── 前回の土台を、もう一段掘り下げる
前回、一般質問をAIと作る支援システムをご紹介しました。その中で、システム全体の土台として「ナレッジ」という層に触れました。今回は、その層の中身を具体的にお話しします。
組み立ては二段構えです。前半は、ナレッジを「どこに置き、どう集めるか」という構築と稼働の話。後半は、集まった素材を、ただの倉庫ではなく使うほどに厚みを増す仕組みへとどう変えていくか、という育成の話です。
出発点 ── PDFを手で並べていた頃
最初のころ、ナレッジベースなどと呼べるほどのものはありませんでした。気になる白書や統計、会議で配られた資料を自分でダウンロードして、MacBook内のフォルダに分類しておく ── ごくシンプルな手作業の蓄積です。「あの資料はどこにあったか」を覚えているうちは回りますが、量が増えてくると一気に持て余します。
転機はClaude Codeを使い始めたタイミングでした。「これなら、ナレッジの収集自体をAIに任せられるかもしれない」という発想が湧いたのです。ここ2ヶ月ほどで、自動収集の仕組みを少しずつ組み立て始めました。整ってきたかな、と思える状態になったのは、ここ1ヶ月未満の話です。
置き場所をどこにするか ── 自宅サーバーへの到達
自動収集の仕組みを本気で回そうとすると、置き場所の問題が最初にぶつかる壁になりました。MacBookのローカルフォルダに貯めていたそれまでの形は、分かりやすい反面、端末がスリープしていたり電源を落としていたりする間は、収集も参照も止まってしまいます。別端末から見ることもできず、議員仲間と共有する導線もありません。
そこで、共有ドライブ系のサービスを一通り試しました。iCloud、Dropbox、Googleドライブ ── いずれもしっくりきませんでした。理由はサービスごとに少しずつ違いますが、大きくは二つに集約されます。一つは、プラットフォームや他サービスに縛られる制約があること。もう一つは、Claude Codeのようにローカルファイルを直接扱うタイプのツールから触りに行こうとすると、挙動が安定せず、自動収集や自動整理の拠点としては頼りにならないこと。
こうした試行錯誤の末に行き着いたのが、自宅に一台サーバーを立てて、そこにナレッジの本体を置くという形でした。ナレッジはローカルファイルシステムで手元に持つのが扱いやすい。ただしMacBookに入れておくと端末の状態に縛られる。ならば、24時間稼働する別のマシンを一台用意して母艦にすればいい ── そういう結論です。
ハードウェアは、新しく買い足したわけではありません。かつてゲーム用に組んでいたものの、最近は使い道なく放置されていたWindowsマシンを再利用しました。OSをUbuntuに入れ替えてサーバー用途に仕立て直しています。「眠っていた機械が、ナレッジの母艦として復活した」という、少し愛着のある経緯です。
MacBookはこのサーバーに対する端末として振る舞うだけ。どの端末からも常に最新のナレッジが見えますし、収集も止まりません。
データ形式 ── PDFはほぼMarkdownに揃えた
サーバー化と並行して、もう一つ大きな見直しを進めてきました。データ形式の全面的な切り替えです。
これまでPDFのまま貯めていた資料を、すべてMarkdown形式に揃える作業を、ここ2ヶ月で進めてきました。理由は二つあります。一つは、PDFはファイルサイズが大きく、件数が増えるとサーバーが重くなるため。もう一つは、AIがナレッジを参照する際の動作負荷、いわゆるトークン消費量を抑えるためです。Markdownは構造化された素のテキストなので、AIにとって読みやすく、参照のコストも軽くなります。
変換そのものも、AIに任せています。PDFから本文テキストを抽出し、目次・見出し・箇条書きなど元の構造を保ったままMarkdownに整形するところまでを、エージェントが自動で進める流れです。表紙や奥付など本文に不要な部分は除き、章立ては可能なかぎり原形を保つようにしています。
現在は、過去に蓄積したPDFの変換はほぼ完了しており、新しく入ってくるPDFが処理待ちの列に並んでいる、という状態です。
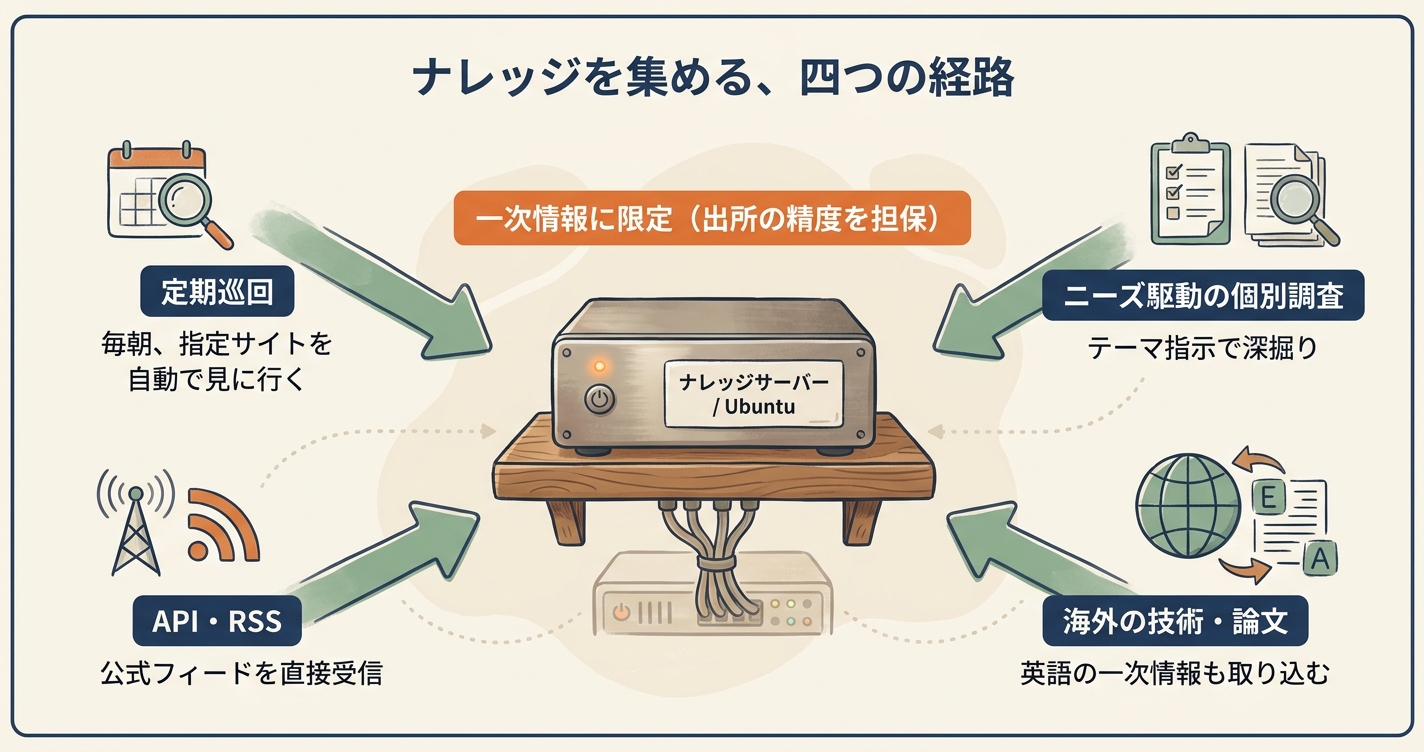
集め方 ── 定期巡回・ニーズ調査・APIとRSS
集め方そのものについても、少し具体に触れておきます。単純なインターネット巡回ではなく、いくつかの手段を組み合わせています。
一つは、あらかじめ指定したサイトを定期的に見に行く巡回です。巡回先は、省庁や道庁の発表ページ、議会資料の公開ページ、信頼できる研究機関のサイトなど、一次情報として精度が担保されているところに絞っています。出所が確かなところしか巡回先に入れない、という運用が、最終的なアウトプットの信頼性を支えます。
もう一つは、ユーザーのニーズに基づく個別の調査です。「この論点について資料を集めたい」というその時々の必要に応じて、AIに調査を任せる。汎用的な巡回では拾えない、テーマ駆動の収集ルートです。
さらに、API連携やRSS購読も併用しています。提供元が公式に配信しているフィードを受け取れるなら、それが最も鮮度と信頼性の高いルートになります。
集める対象は国内に限りません。海外の動向、特に技術系や論文系の最新知見は、議員業務に直接効いてくる場面が増えています。AIに英語の一次情報を読ませて要点を返してもらえるようになったことで、海外情報を積極的に取り込むハードルが大きく下がりました。
格納の際には、すべての資料に取得日時・取得元のURL・ジャンルが必ず付与されます。連載「議員とAI」第2回でトレーサビリティと呼んだ考え方を、仕組みのレベルに落とし込んだ部分です。
朝のレポートで、動きを把握する
自動で動き続ける仕組みは、走らせっぱなしにすると何が起きているか見えなくなります。そこで毎朝、前日の動きをまとめた短いレポートが手元に届くようにしています。新着件数、ジャンル別の傾向、エラーの有無。A4一枚に満たない分量です。
毎日じっくり読むわけではありませんが、「今日も動いているな」と確かめられる小さな窓があるだけで、仕組みとの関係が保てます。
ここまでが「構築と稼働」の話
サーバーに置かれた倉庫があって、毎朝自動で材料が集まり、古いものは退き、出所と鮮度が記録され、朝のレポートで全体を眺められる。ここまでで、AIが議員業務を支える土台としては十分機能します。
しかし、ここから先にもう一段の景色があります。倉庫を倉庫のままで終わらせず、「使うほどに厚みを増す場所」に変えていく段階です。後半はその話に入ります。
倉庫のままでは、知見にならない
ナレッジベースに情報が大量に集まってくると、ある時期からこんな感覚に襲われました。
材料は揃っているはずなのです。検索をかければ関連資料は何本もヒットする。しかし「このテーマの論点を整理したい」というとき、大量の資料を前にどこから手をつけてよいか分からなくなる。結局、毎回ゼロから読み直し、要点を頭で組み直すことになります。
これは情報の不足ではなく、「蓄積されているだけ」の状態が生む壁でした。テーマをまたいで横断された知見、過去に自分がたどり着いた理解の記録は、どこにも残っていません。倉庫が大きくなるほど、この問題はむしろ深刻になりました。
Wikiのように育てる、という発想
そのころ出会ったのが、AI研究者として知られるAndrej Karpathy氏が言及していた、ある発想でした。下の層に原典そのままの資料を蓄積し、上の層にLLMが原典を読み込んで合成した「Wiki風のページ」を置く。下は増え続ける倉庫、上は使うほどに書き足されていく辞書、という二層構造です。
この発想がそのまま、私のナレッジベースの後半を形づくっています。

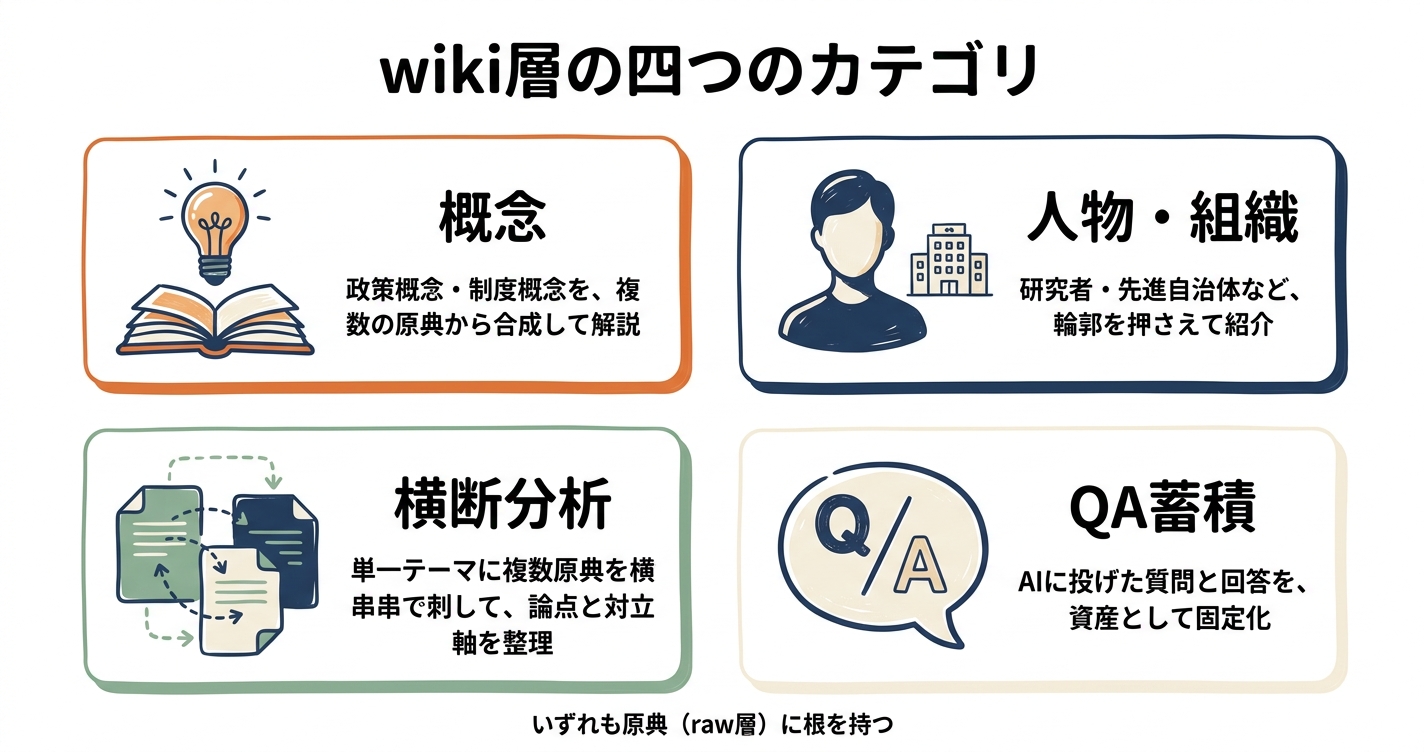
育つ層の四つのカテゴリ
私の場合、Wiki層は四つのカテゴリに分けています。
- 概念のページ:自治基本条例、議会基本条例、デジタル民主主義といった政策概念について、複数の原典を合成した解説
- 人物・組織のページ:地方自治研究の研究者や、議会改革の先進自治体について、輪郭を押さえた紹介
- 横断分析のページ:単一テーマに複数の原典を横串に刺して、論点と対立軸を整理した文書
- QA蓄積のページ:AIに投げかけた質問と回答をそのまま資産として固定化したもの
いずれも、原典の倉庫に根を持っています。Wiki層は独立した文書ではなく、raw層の上に咲いた花のような位置づけです。
二つの読み手が、同じWikiを使う
この育つ層には、読み手が二種類います。
一人は、私自身です。ナレッジベースの全体を俯瞰し、概念ページから論点を掴み、横断分析で深掘りする。「あの議論、どこまで考えていたっけ」と思い出すときの足場として機能します。
もう一人の読み手は、AI自身です。エージェントがナレッジを参照するとき、いきなり大量の原典に当たるよりも、Wiki層で要点が整っているほうが圧倒的に速く、的確に動きます。同じ階段を、人間とAIが両方から登る ── そういう設計です。
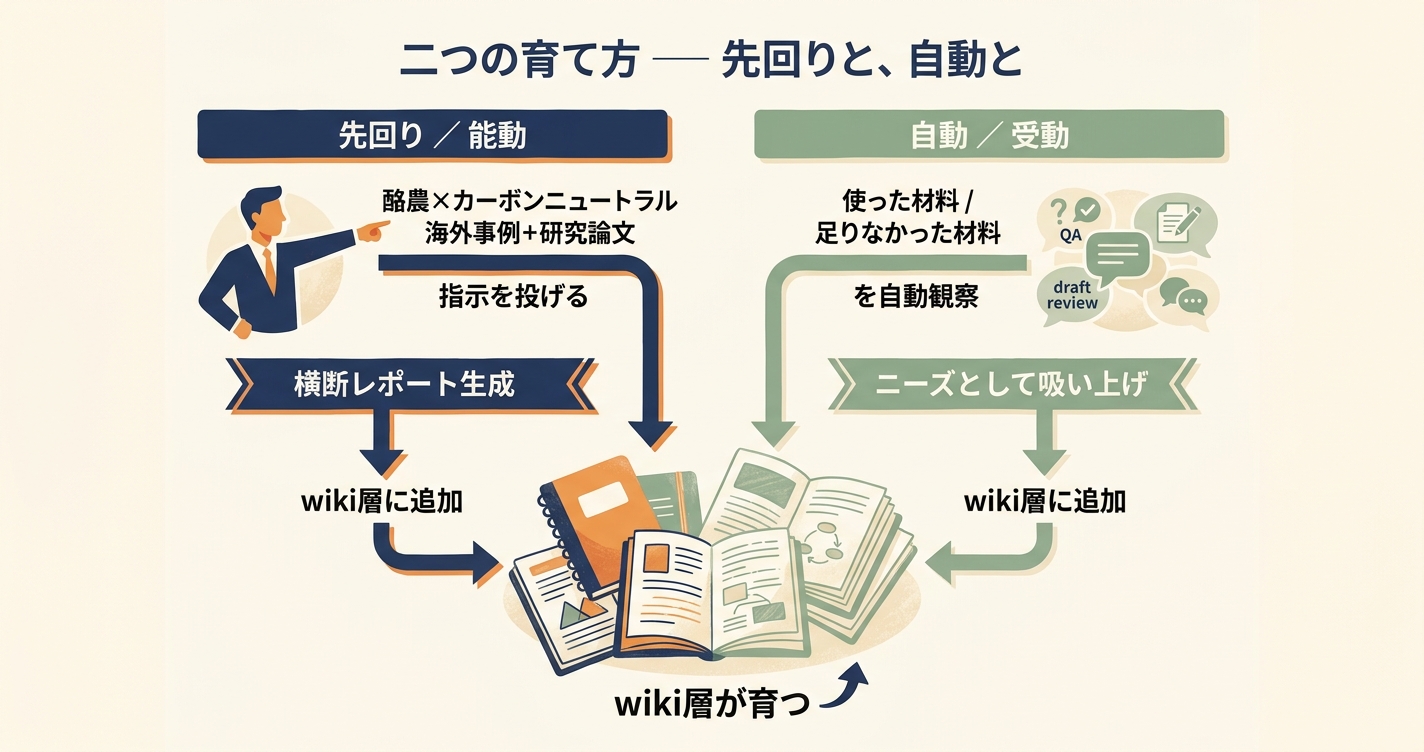
先回りで、ナレッジを厚くしておく
Wiki層の育ち方には、大きく二つの筋があります。一つは、テーマを見据えて能動的に先回りで厚くしていく方向。もう一つは、日々の業務のやり取りを通じて自動で育っていく方向です。順にご紹介します。
一つ目の「先回り」は、たとえばこんな使い方です。一般質問の検討に入る前、「酪農のカーボンニュートラルへの取り組みについて、国内外の事例や科学的裏付け、研究論文を横断して調べておいて」と指示を投げておきます。すると、サーバー側のエージェントがナレッジベースに関連素材を追加で取り込み、それらを横断したレポートを一本まとめ上げてくれる。
私はその作業に実際に入る前に、このレポートを一読します。頭のなかに地形図を入れた状態で作業に着くのと、白紙のままその場で調べながら進めるのとでは、進みの速さも深さもまるで違います。
この使い方は、前回ご紹介した一般質問作成支援システムとの相性が、とりわけ良いものになっています。立てたい質問のテーマを事前に決め、その周辺をナレッジ側で先に厚くしておく。作業当日までに材料が揃い、レポートで全体像が見えている。この下ごしらえがあるかないかで、質問の密度ははっきり変わる ── というのが、運用してみた実感です。
自動で育つ仕組み ── やり取りをニーズとして吸い上げる
もう一つの育ち方は、日々の業務のやり取りそのものが、Wiki層を育てる栄養になる経路です。
材料は、QAのやり取りだけではありません。一般質問作成支援エージェントとの起案のやり取り、日常的にAIに対して行う「壁打ち」の対話、議会運営相談で交わされる論点整理 ── そうした業務のあらゆる対話を、仕組みのほうが背後で観察しています。
その観察から、二種類の手応えが拾われます。一つは「使った材料」。どの原典が頻繁に参照され、どの概念ページが何度も呼び出されたか。これが分かれば、Wiki層のどこを優先的に厚くすべきかが見えます。もう一つは「足りなかった材料」。AIに質問しても満足な回答が得られなかった瞬間、その不足は痕跡として記録されます。海外事例が出てこなかった、特定の研究者の見解が確認できなかった、似た政策課題の他自治体の資料がなかった ── そうした穴が、次の収集対象や次のWiki更新候補として上がってくる。
最初は、私が「次はこれを集めよう」「ここをまとめ直そう」と指示していました。しかし今は、仕組みのほうから「次はこれが必要そうです」と声が上がる。受動的な倉庫が、能動的な調達と整理のシステムへ育ってきた、そういう手応えがあります。
おわりに ── 蓄積から成長へ
ナレッジベースは、一度構築して完成する類のものではありません。毎朝の巡回で材料が増え、先回りの指示で特定テーマが厚くなり、日々のやり取りからWiki層が自動で書き足されていく。静かに、しかし着実に育つ仕組み。
連載「議員とAI」で考え方を、前回のプロジェクト紹介で実装の最初の応用を、そして今回はその土台が育つ生き物のような姿になっていることを、お伝えしてきました。派手さのない、地味な仕組みです。しかしAIを本当に活かそうとするなら、この土台がなければ始まりません。
次回以降のプロジェクト紹介では、このナレッジの上で動いている、別のプロジェクトを順にご紹介していきます。